
Survey of GraphQL Cost Analysis in 2021: Products and Academia
Which products provide GraphQL Cost Analysis in 2021, and which methods are they using? Which methods are discussed in academic research papers?
This article is Part 5 in a 7-Part Series. (7 posts to date, more planned)
- Part 1 - Why does GraphQL need cost analysis?
- Part 2 - Methods of GraphQL Cost Analysis
- Part 3 - GraphQL Static Analysis Example
- Part 4 - Survey of GraphQL Cost Analysis in 2021: Public Endpoints and Open Source Libraries
- Part 5 - This Article
- Part 6 - Introducing: GraphQL Cost Directives Specification
- Part 7 - API Days Interface: GraphQL Cost Directives Specification
I’ve discussed why GraphQL cost analysis is important, and the three high-level methods of calculating GraphQL cost, as well as what prominent public GraphQL endpoints and open source libraries are providing.
Next, we survey a few concrete examples in the following areas:
If you just read the last post, you can skip down to my discussion of the products.
As with the last post, the goal here is not to survey every use, but rather to look at a few of each type to gather a sense of the various options for cost analysis and the tradeoffs being made.
These assessments are based on public documentation. Where documentation is vague, I’ve tried to accurately represent that in my assessment. For example, where a server calculates an actual cost, is it doing Dynamic Query Analysis or Query Response Analysis? I’ve tried to indicate whichever one the text of the documentation hinted at, but if someone wants to correct me please let me know and I can update this page.
Terminology
This is important terminology, the same as the last post:
- For the methods of GraphQL cost analysis, I’m using Static Query Analysis, Dynamic Query Analysis, and Query Response Analysis as defined in an earlier post.
- Field Cost is a GraphQL cost metric that estimates how expensive it is for the GraphQL server to execute a query.
- Type Cost is a GraphQL cost metric that estimates how much data will be returned over the wire as a response to a query.
- Threat Protection is stopping a query before its executed because there is too high a cost for that single query.
- Rate Limiting is limiting the total cost incurred from running queries over a time interval.
- Monetization can involve charging an API consumer based on the cost of the queries they send.
- Slicing Arguments are arguments on a GraphQL field which express the maximum size of a returned list.
There are many other names used for Slicing Arguments, including Pagination Arguments, Limit Arguments, List Arguments, and Size Arguments. We have chosen to use Slicing Arguments because the GraphQL Foundation learn pages define this process as slicing, as does the Relay Connections Spec.
Products
Besides open source standalone libraries and specific custom endpoints, you can also look at GraphQL API Management solutions and GraphQL servers and what they have to say about GraphQL cost analysis.
IBM API Connect
IBM API Connect is an API Management solution which proxies requests to a backend GraphQL server, performing Static Query Analysis and Query Response Analysis. Both of these methods compute each of:
- Field Cost to model the amount of work on the server.
- Type Cost to model the amount of data returned over the wire.
The results can be used for threat protection and rate limiting. It also provides query depth calculation for threat protection.
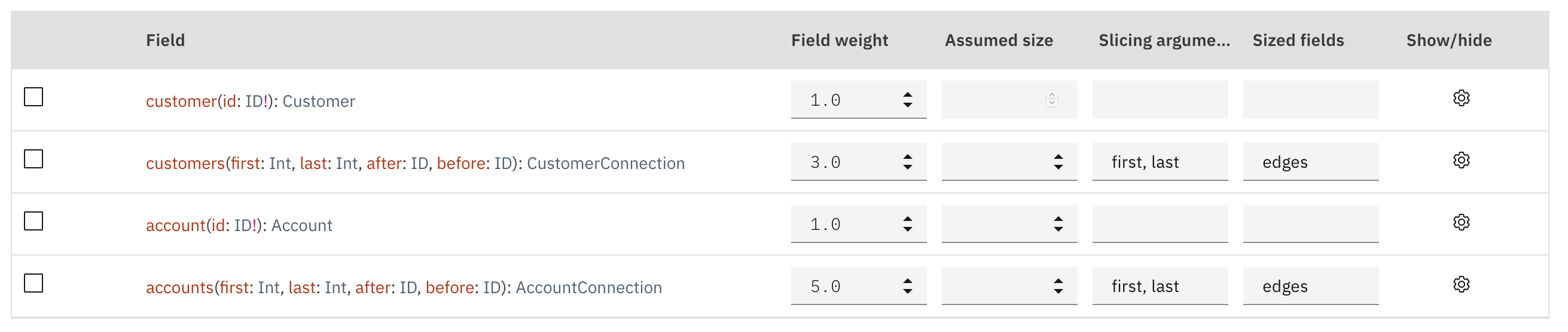
This product allows extending the SDL to express the slicing arguments and custom weights for GraphQL schema types and fields.
type Query {
users(filter: Filter): [User] @listSize(slicingArguments: ["filter.max"])
}
Here’s a screenshot from the product showing configuration of slicing arguments and custom cost weights:
For threat protection, parse settings for GraphQL payloads include maximum document size and maximum document depth, as can be seen in this screenshot:

Note: I work on this product, but I am writing here as a private individual and this section is limited to public information.
Hasura
Hasura offers a hosted GraphQL engine including many pieces of built-in infrastructure around the GraphQL engine. It provides various security features including threat protection using the depth of the query. While this is a form of cost analysis, we generally consider it a separate category.
Here is a screenshot from the linked webpage in Hasura’s documentation. While the rate-limit is based on requests per minute and not based on any cost analysis, they provide threat protection based on the query depth. Note that this depth limit may be places per group of API consumers sharing a single role. While this limits you from being able to configure the limit per-consumer, you will usually have many consumers per-role so the management can be much easier.
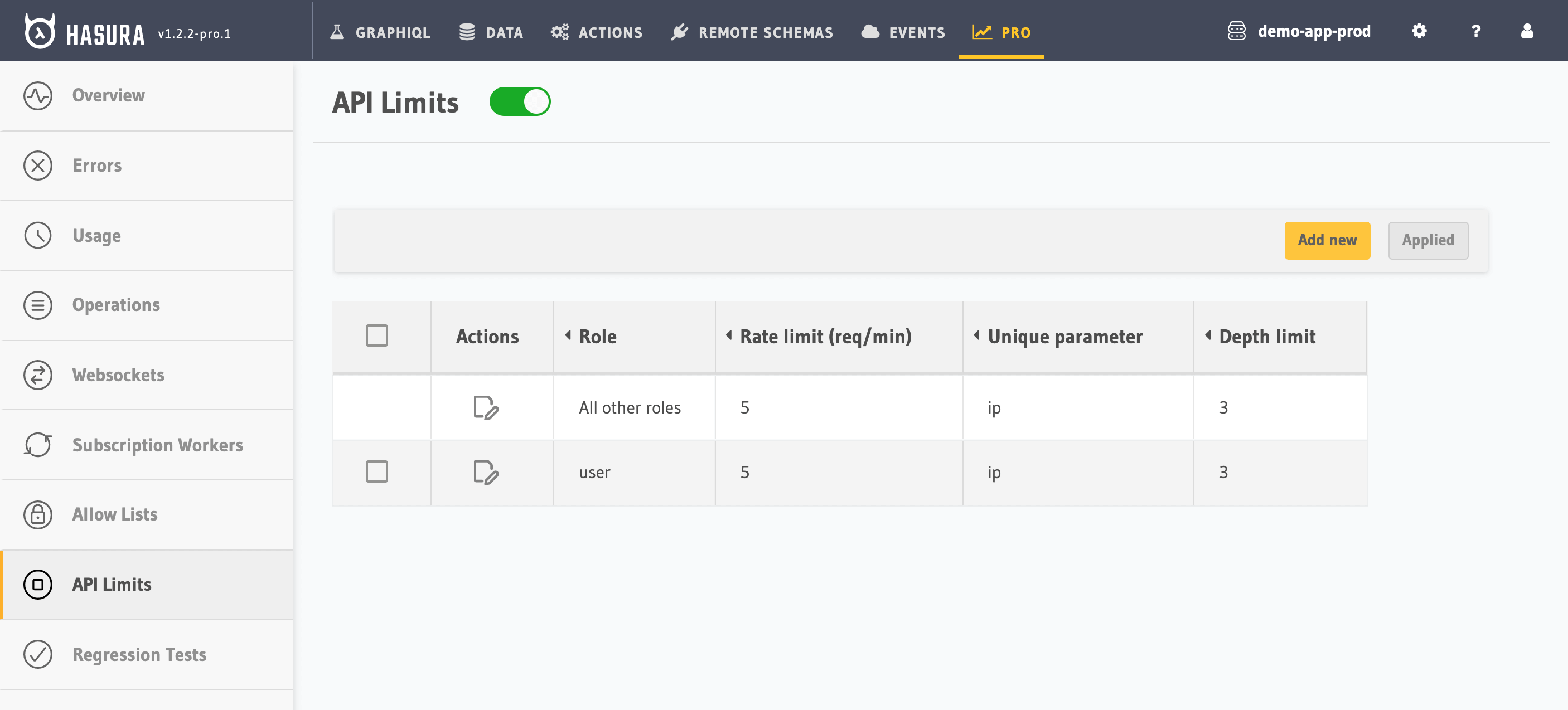
Note that Hasure exempts introspection queries from the depth limits.
Tyk
Tyk is an open source API Management solution which proxies requests to a backend GraphQL (or non-GraphQL) server. Like Hasura, it also provides various security features including caclulating the depth of each GraphQL query for threat protection, but does not yet advertise a more general form of cost analysis.
Here is a screenshot from the linked webpage in Tyk’s documentation. Note that Tyk allows the depth-limit to be on an API key, which means you can configure this depth limit per API consumer. While a per-role configuration might be easier to manage, this per-consumer capability allows full fine-grained control.

WSO2
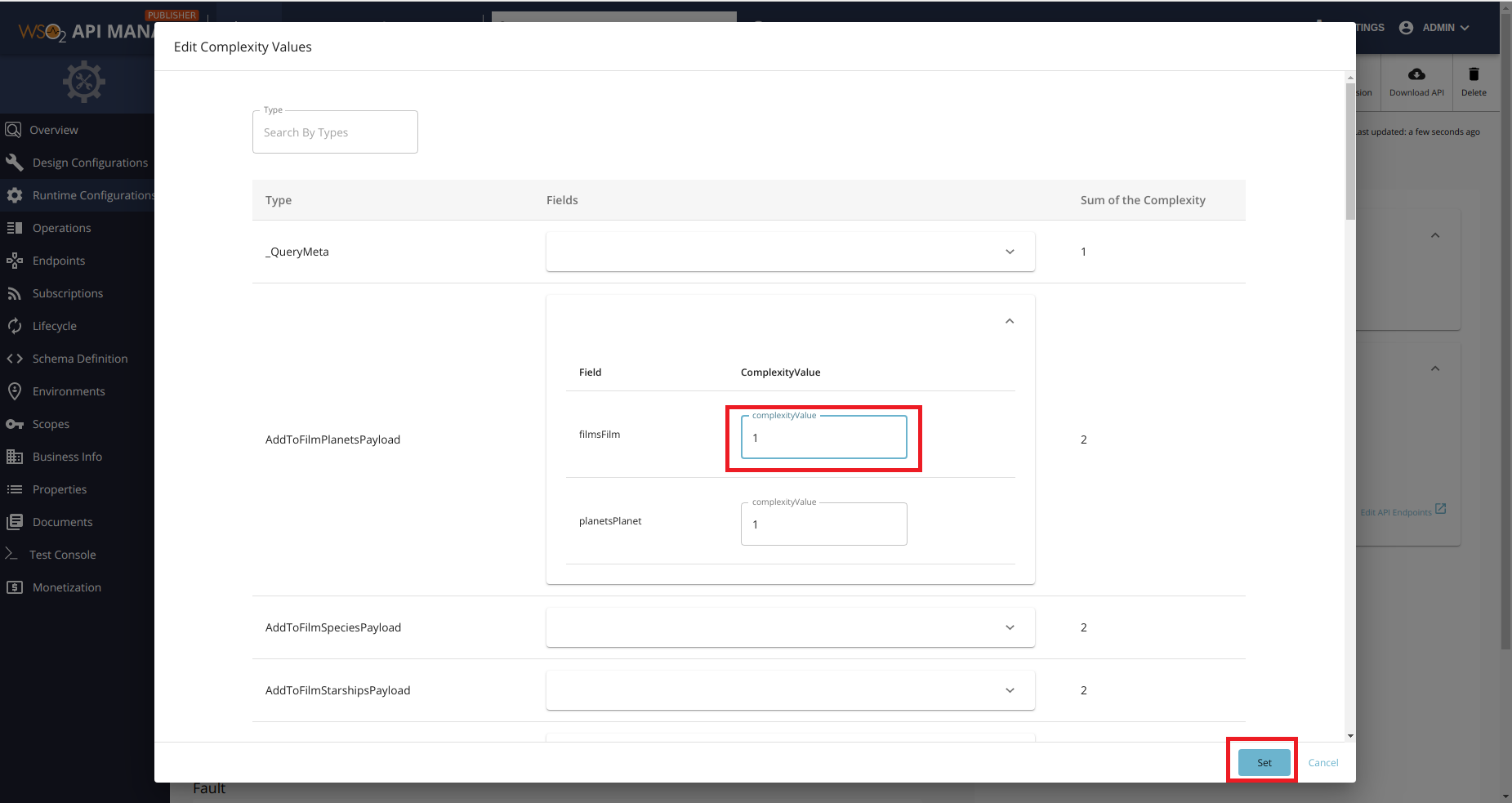
WSO2 is also an open source API Management solution which proxies requests to a backend GraphQL server. WSO2 provides threat protection based on both the depth of the query and also a Static Query Analysis which is configured by specifying slicing arguments and weights for fields in your GraphQL schema.
Here are two pictures from the link to their documentation. The first one shows adding a custom cost weight for certain fields in the schema:
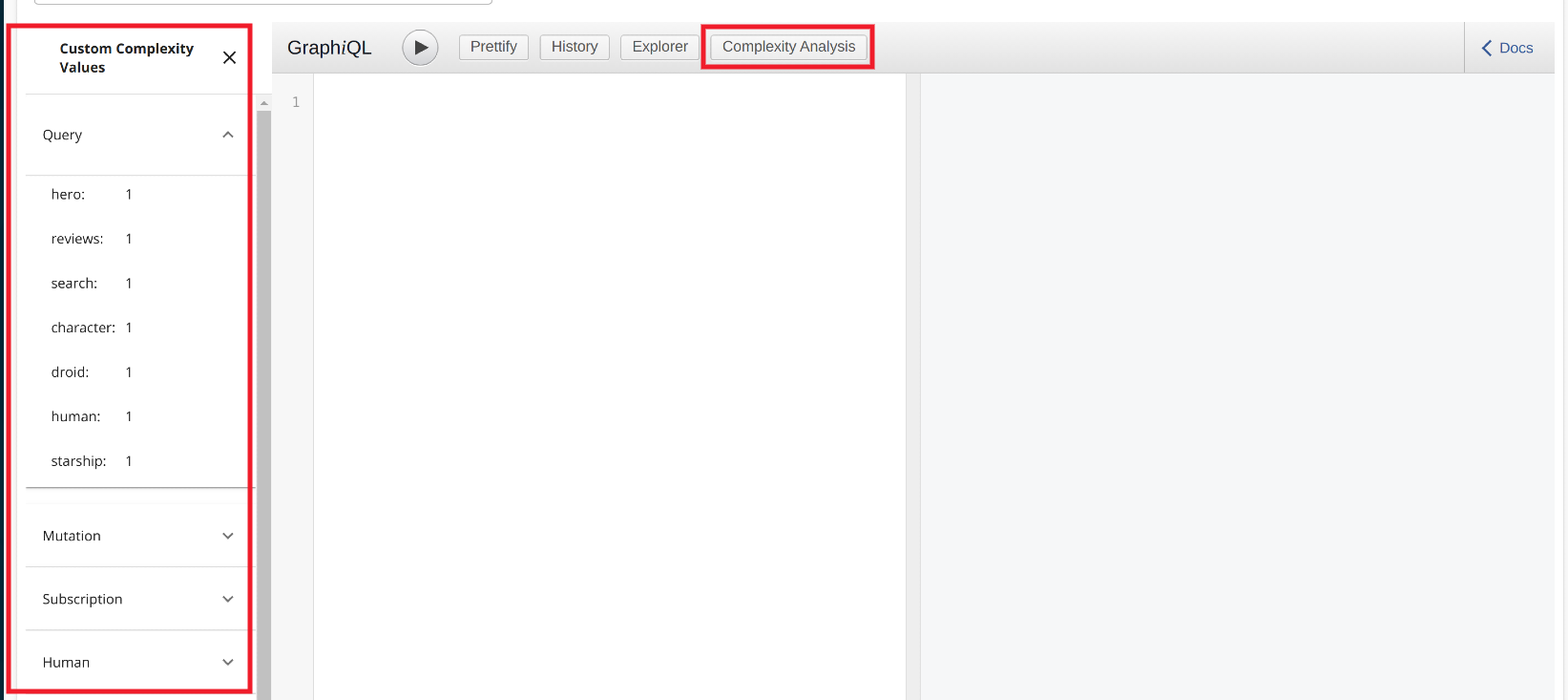
The second picture shows their plugin to GraphiQL which advertises the custom cost weights to the API consumer:
Sangria
Sangria is the open source GraphQL implementation in Scala. Sangria provides two related capabilities:
- Calculating the depth of the query for threat protection
- Using Static Query Analysis as a built-in capability in the library, based on custom cost functions provided per-field. The result can be used however the Scala caller desires.
Here is an example of enforcing a maximum query depth:
val executor = Executor(schema = MySchema, maxQueryDepth = Some(7))
Here is an example of using a custom Scala function on a field to compute the cost of running the associated resolver function. Note that both the custom weight and the list of slicing arguments is built in to this function, but since it is a full function it can use arbitrary complexity in its algorithm. Overall, it is much more powerful and consequently more complicated to use.
Field("pets", OptionType(ListType(PetType)),
arguments = Argument("limit", IntType) :: Nil,
complexity = Some((ctx, args, childScore) ⇒ 25.0D + args.arg[Int]("limit") * childScore),
resolve = ctx ⇒ ...)
The powerful ability of a general function matches slicknode/graphql-query-complexity, which was modeled after Sangria.
Research
In April 2018, Olaf Hartig and Jorge Pérez published Semantics and Complexity of GraphQL at the 2018 World Wide Web Conference. One of their findings shows a theoretical bound for computing GraphQL Type Cost of polynomial time. In their words:
We provide a solution to cope with this problem by showing that the total size of a GraphQL response can be computed in polynomial time.
They set up a strict formalization of GraphQL, which is useful beyond their work, to enable this proof. Their computation, in our terminology, is Dynamic Query Analysis, because it uses information from either the backend data source or the GraphQL execution engine. However, they optimize it with knowledge of the backend data to be mostly before query execution.
Without that extra information, they write that:
GraphQL service providers must impose severe restrictions on the structure of the queries or the data.
In situations where you are doing Dynamic Query Analysis, their approach is a wonderful one to:
- minimize the drawback of dynamic analysis: wasted effort before stopping bad transactions
- retain the prime asset of dynamic analysis: more accurate bounds on predictions
In situations where probing the backend is too costly and you require Static Query Analysis, their earlier analysis is still relevant, but needs to be expanded on. This occured academically in November 2020, when friends of mine at IBM Research published A Principled Approach to GraphQL Query Cost Analysis, which won a distinguished paper award at ESEC/FSE 2020. One of the authors also wrote up their findings in a blog article.
Cha et.al. present an approach to Static Query Analysis for both Type Cost and Field Cost (which they call “resolver complexity”), with their key contribution being the ability to compute the cost of a query independent of the backend. As we’ve seen, this comes with an inherent tradeoff that the bounds of the estimate are not as tight, but this paper shows that with sufficient configuration the bounds can be much tighter:
With proper configuration, our analysis offers tight upper bounds, low runtime overhead, and independence from backend implementation details.
Overall, these two papers are important contributions to the landscape of methods of GraphQL cost analysis, each minimizing the limitation of one of the key methods:
- Hartig and Pérez provide an algorithm of Dynamic Query Analysis which minimizes the extra work involved.
- Cha et.al. provide an approach of Static Query Analysis which minimizes the overestimation of cost.
Persisted Queries
Our survey of cost analysis in the industry cannot be complete without one more topic: human-calculated cost. It is common for many GraphQL endpoints to limit the number of queries that they accept. Apollo GraphQL provides this support as persisted queries, while others call it whitelisting queries or allowlisting queries.
You can think of this as an analogy to stored procedures in SQL. Each persisted query is developed either in-house or by a business partner, but always at development time. Each of these pre-approved queries has been code reviewed by an engineer on the server team and determined to be safe enough. Each pre-approved query then gets its own cost for rate limiting and monetization, and there’s no concern for threat protection.
Sometimes this is the a priori plan. Other times, a company decides to move to GraphQL first and later realizes that they are in trouble without cost analysis, so instead they only allow a set of pre-approved GraphQL queries.
Either way, this is basically a hybrid between REST and GraphQL. One way to think of it is as a REST endpoint that is internally implemented using GraphQL.
This approach can be a good one to make the cost analysis significantly easier, especially if the only clients are internal or business partners with very close relationships to the GraphQL provider. Either of these relationships assures quick turn-around time from the server team, thus not losing much of the advantages of GraphQL.
Sometimes this approach can be combined with defining a custom scalar type for slicing arguments. This custom scalar is an integer that is not allowed to get large, thus decreasing the number of checks needed to ensure small list sizes are returned from a query.
In this article the important point is that persisted queries are still doing GraphQL cost analysis for every query. The difference is that they are doing that cost analysis in advance and by a human engineer instead of after establishing an HTTP connection and by an algorithm.
Summary
Every one of the products I discussed provides threat protection based on the depth of the GraphQL query. This makes sense since it is a simple form of cost analysis which is easy to implement, quick to run, and can restrict some very unsafe queries. It is one of the recommended protections in the OWASP Cheat Sheet for GraphQL.
The academic papers have ‘paved the way’ for optimizing the various methods of GraphQL cost analysis. About half of the open source projects and about half of the products follow this path and go further than depth limiting, with some form of GraphQL cost analysis. It is clear that this is of vital importance and I expect the percentage providing real cost analysis to grow over time.
Clearly major public endpoints would need cost analysis, as real money is at stake, and for the group I discussed:
- Every one of them publishes their rules and limitations on queries.
- Every one of them uses cost analysis based on both custom cost weights and knowledge of slicing arguments.
- Every one of them uses cost analysis for specialized GraphQL cost-based rate limiting.
- Two also use cost analysis for threat protection, while one does not.
- One uses Type Cost, one uses Field Cost, and one uses both.
- They use different methods of GraphQL cost analysis, with most using multiple methods.
It seems clear to me that the products and standalone open source libraries are catching up to the “hard lessons” already learned at the companies running major public endpoints. I expect both the products and open libraries to evolve significantly in the next year or two.
Anything I got wrong when working from the online documentation? Please let me know so I can update it.
Do you have more examples of products or open source using GraphQL cost analysis? I can add links here.
What evolution do you think we’re likely to see in these products?
This article is Part 5 in a 7-Part Series. (7 posts to date, more planned)
- Part 1 - Why does GraphQL need cost analysis?
- Part 2 - Methods of GraphQL Cost Analysis
- Part 3 - GraphQL Static Analysis Example
- Part 4 - Survey of GraphQL Cost Analysis in 2021: Public Endpoints and Open Source Libraries
- Part 5 - This Article
- Part 6 - Introducing: GraphQL Cost Directives Specification
- Part 7 - API Days Interface: GraphQL Cost Directives Specification